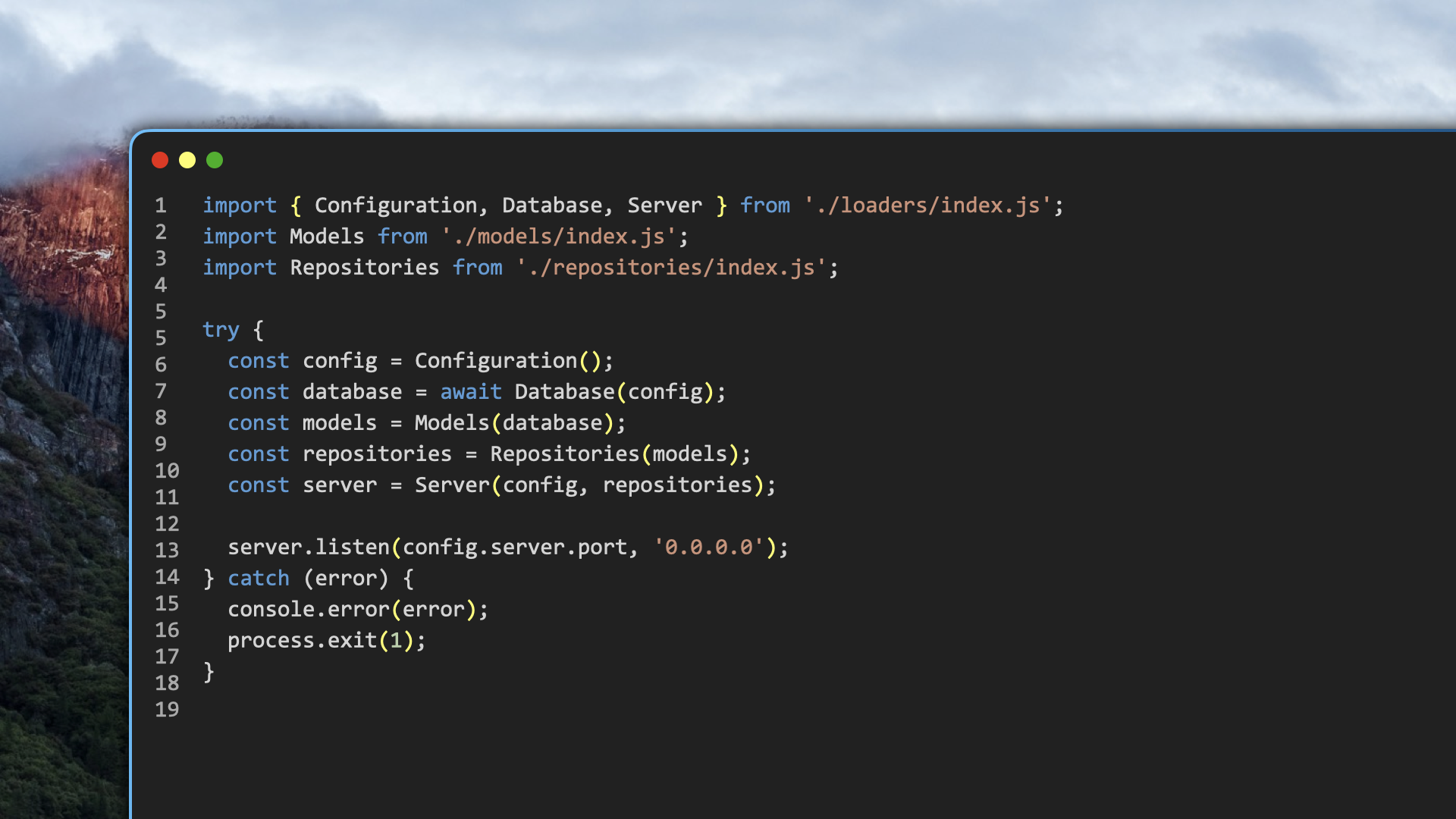
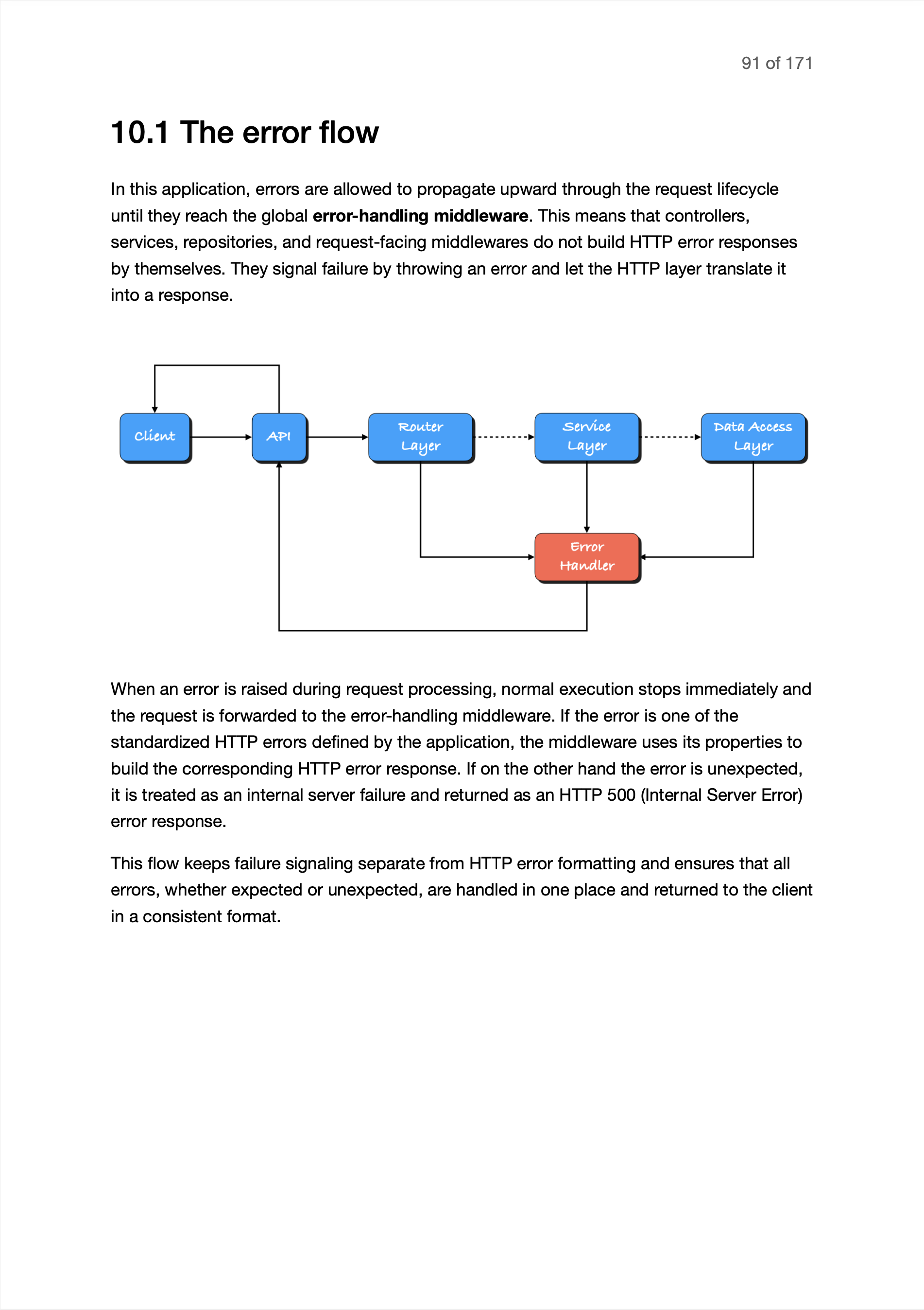
Build Your Next Express API From a Trusted Standard
Get the API blueprint, architecture handbook, and implementation recipes I use to structure Express APIs with clean layers, validation, configuration, persistence, and centralized errors.
"I wasted months trying to figure out how to build consistent APIs. Problem solved."
Jean-Baptiste M.
Full Stack Developer
What You Get in the Pack
Most boilerplates give you files. This gives you a building standard.
The Express Build Pack gives you everything you need to start building production-grade Express APIs, so you can start every new project with one clear way of wiring the whole application together.

An Express API scaffold that includes the essential plumbing of the API. It gives you a working foundation with the architecture, request flow, middleware, validation, configuration, error handling, and persistence already wired in.
A technical handbook that explains the rules behind the three-layer architecture. It defines how the API is bootstrapped, how its layers are structured, how they interact with each other, and how the whole system stays consistent as it grows.
A practical playbook that shows how to extend the API without breaking its architecture. It gives you step-by-step implementation recipes for defining API contracts, modeling database entities and adding new endpoints.
30-day refund guarantee. No questions asked.
"My API is a mess, but I don't know how to fix it"
You've probably gone through dozens of tutorials, looking for yet another pattern that will help you fix your API. But in practice, every new pattern you introduce contradicts existing ones, making your codebase increasingly difficult to work with.
So instead of shipping, you keep moving things around and waste time reinventing how configuration is parsed, where business logic lies, or how errors are handled, until your spaghetti code turns into spaghetti architecture.
Here's the problem: you're building without a standard. Without a set of coherent rules that enforce how to bootstrap your API, structure it into clean layers, define how those layers interact, and keep your codebase consistent.
This is why I created the Express Build Pack.
Who This Pack is For
This is PERFECT for you if:
You already know Node.js and basic Express
You've built APIs before
You're tired of every project ending up structured differently
You want a repeatable way to add endpoints, validation, persistence, and errors without improvising every time
This is NOT for you if:
You want a beginner-friendly "learn Node from scratch" course
You want hours of video content
You are looking for a toy CRUD demo
You are not yet comfortable reading and modifying backend code
The API Blueprint
The build kit includes a prewired Express API blueprint with the components needed to implement the three-layer architecture.
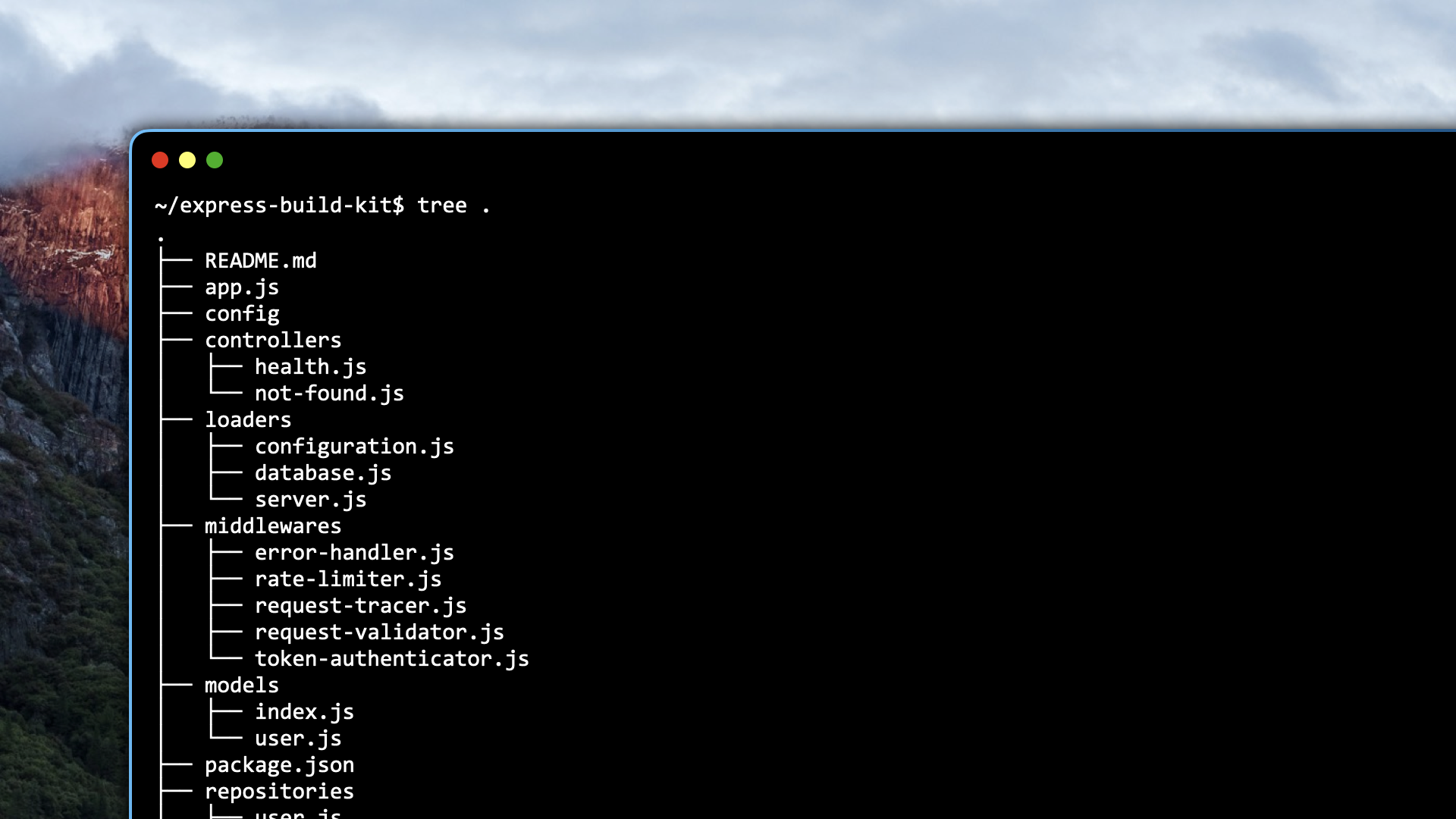
So instead of spending your first hours rebuilding the same plumbing, you start from a working foundation that already follows one clear standard.
Here's what you'll get from it:
Clean ECMAScript modules
A predictable project structure where routes, controllers, services, repositories, models, schemas, loaders, docs, and shared code each have a clear place.
Native Node.js configuration loader
A dedicated startup system that loads, validates, maps, and injects configuration before the rest of the application is initialized.
Prewired Express request pipeline
A complete Express request flow already wired from routing and validation to business logic, persistence, responses, and centralized errors.
Joi request validation system
Boundary-level validation for request bodies, route params, and query values so invalid input does not leak into the service layer.
Built-in endpoint rate-limiting
Protects selected endpoints from excessive traffic by applying request limits where abuse, spam, or accidental overload are most likely to happen.
Standardized & centralized error-handling
A single error-handling path that turns application errors into consistent HTTP responses instead of formatting failures in every controller.
Extensible Sequelize ORM structure
A persistence structure that separates models, repositories, and database access so the API can grow without spreading queries everywhere.
Health & fallback endpoints
Health check, fallback, and example endpoints included to demonstrate the structure and give the API useful defaults from the start.
OpenAPI documentation
A dedicated documentation setup for describing endpoints clearly and keeping the API contract easier to inspect as the project grows.
30-day refund guarantee. No questions asked.

The API Architecture Handbook
The build kit includes a complete implementation handbook that explains the design, conventions, and rules behind the API's three-layer architecture.


Each part is written as a short technical reference you can come back to whenever you need to understand how the API is wired, how its layers interact with each other, or how features are implemented without breaking the overall structure.
Here's an overview of what's in it:
Layer boundaries
Defines what each layer is responsible for so routing, business logic, and database access do not get mixed together as the API grows.
Naming conventions
Gives consistent naming rules for files, folders, modules, and architecture pieces so the codebase stays easier to scan and extend.
Configuration policy
Shows how environment variables are loaded, validated, mapped, and exposed through a clean configuration object before the app starts.
Request lifecycle
Explains how a request moves through the application, from the router to validation, services, persistence, responses, and error handling.
Validation rules
Defines where request validation belongs, what should be validated, and how invalid params, query values, and payloads are rejected.
Persistence rules
Explains how database access is isolated behind repositories so business logic does not depend directly on ORM models or queries.
Response contract
Defines how successful API responses are shaped so clients receive predictable data instead of route-specific response formats.
Error contract
Defines how application errors are normalized, exposed, and returned so clients can parse failures consistently.
30-day refund guarantee. No questions asked.
The Recipes Playbook
The built kit also comes with a recipes playbook that turns the architecture from the handbook into a complete authentication flow.




It follows a bottom-up implementation approach, starting from the database structure and moving through models, repositories, providers, services, controllers, routers, configuration, validation, and manual endpoint testing.
API contracts
Defines the request, success response, error responses, and side effects for the signup, email verification, and login endpoints.
User entity modeling
Shows how to create the users table, map it to a Sequelize model, and expose database operations through a repository.
AWS provider integration
Implements a dedicated provider for sending verification emails while keeping third-party service details outside the Service layer.
Signup flow
Builds the full signup feature, including request validation, password hashing, verification token generation, user creation, email delivery, controller wiring, routing, and manual testing.
Email verification flow
Implements the endpoint that receives a verification token, validates it, retrieves the matching user, marks the account as verified, and clears the token.
Login flow
Implements the endpoint that validates credentials, checks account status, compares password hashes, generates a JWT, and returns it through a consistent response.
Configuration updates
Shows how new environment variables for AWS and JWT signing are added to the configuration files and validation schema.
Manual endpoint testing
Provides curl-based checks for success and failure cases, including validation errors, conflicts, unauthorized requests, forbidden access, and successful responses.
30-day refund guarantee. No questions asked.

Hi, I'm Razvan
I'm a senior Node.js developer with 15 years of professional experience building backend systems for startups like SnapCall, Planity, Trusk, Kapten, FreeNow, and more.
For the past 5+ years, I've turned that experience into 100+ articles, 30 videos, 3 books, and 2 full-scale courses.
LearnBackend.dev is where I teach backend development the way I believe it should be taught: through clear principles, real implementation, and reusable standards you can apply beyond the lessons.
Stop rebuilding APIs from scratch
Get a trusted and reusable standard for structuring, extending, and maintaining cleaner Express APIs.

Questions You Might Have
Why should I trust this standard?
Because it does not come from theory alone. It comes from years of working with backend architectures, from the work behind Build Layered Microservices, and from real implementation in projects like LearnBackend.dev.
What problem is this supposed to solve?
It solves the lack of consistency that appears when APIs are built by patching together tutorials, boilerplates, and one-off fixes. The goal is to give you one clear standard for bootstrapping, structuring, and extending an Express API.
Is this just another boilerplate?
No. A boilerplate gives you code to start from. The Express Build Pack gives you a reusable standard for how the API is structured, how its layers interact, how requests flow through the application, and how new code should be added consistently.
Can I use it for a real project?
Yes. The whole point is to give you a standard you can actually build on. It is designed to help you start production-grade Express APIs with a cleaner foundation, while still leaving you in control of your own business logic and product-specific decisions.
How will I get the build pack?
Once your payment is processed, you'll immediately recieve a direct download link via email to download the handbook and the source code in the ZIP format.
What if I'm not satisfied with this product?
If for whatever reason you're not satisfied with this product, you can send me an email within the first 30 days of your purchase and I'll refund your entire payment. No hard feelings, no questions asked.
I've got more questions
Send me an email at support@learnbackend.dev, I'll get back to you within 1-2 business days.
Get 2 Sample Chapters
Sign up and get 2 free chapters from the implementation handbook including the architecture's overview and the application bootstrapping.